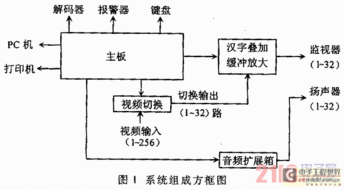
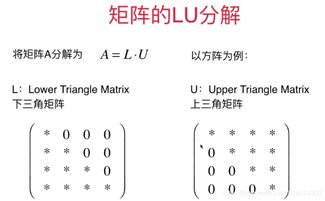
Java環境下Memcached分布式原理、實現與在矩陣系統中的應用
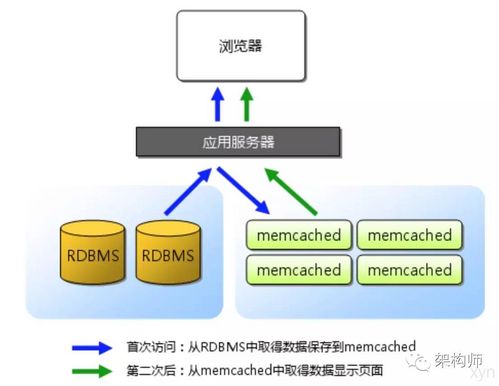
Memcached是一款高性能、分布式的內存對象緩存系統,廣泛應用于減輕數據庫負載、提升動態Web應用速度。在Java生態中,通過客戶端庫(如Spymemcached)可以便捷地集成和使用Memcached。本文將深入探討其分布式原理、在Java中的實現方式,并分析其在復雜系統(如矩陣系統)中的應用場景與價值。
一、Memcached分布式核心原理
Memcached本身服務端是“分布式”的,但這里的“分布式”并非指服務端集群內部有通信和協調(事實上,每個Memcached服務實例都是獨立、對等的),而是指由客戶端驅動的分布式邏輯。其核心原理基于一致性哈希算法。
- 數據分片與存儲:客戶端將需要緩存的數據(key-value對)存儲到多個Memcached服務器節點中。關鍵問題在于如何決定一個給定的key應該存到或取自哪個服務器節點。
- 一致性哈希算法:這是實現分布式的核心。算法將所有可能的哈希值構成一個環(通常為0 ~ 2^32-1)。
- 服務器節點映射:對每個服務器節點(通過IP、端口等標識)進行哈希計算,將其映射到哈希環上的某個位置。
- 數據鍵映射:對每個數據的key進行同樣的哈希計算,也映射到環上。
- 數據歸屬:從數據key在環上的位置出發,沿環順時針查找,遇到的第一個服務器節點,即為該key所屬的節點。
- 優勢:
- 可擴展性:當增加或移除服務器節點時,一致性哈希能保證只有該節點附近(逆時針方向)的一部分數據需要重新映射,大部分數據的位置保持不變,避免了全局重新哈希帶來的“緩存雪崩”問題。
- 負載均衡:通過引入“虛擬節點”的概念(即一個物理節點在環上對應多個哈希點),可以更均勻地分散數據,防止個別節點負載過重。
二、Java客戶端實現分布式
在Java應用中,我們并不直接實現Memcached服務器,而是使用客戶端庫來管理與多個Memcached服務器節點的交互,并實現上述分布式邏輯。以常用的Spymemcached客戶端為例:
1. 連接管理:客戶端維護一個與所有配置的Memcached服務器節點的連接池。
2. 哈希算法集成:客戶端內置了一致性哈希算法的實現(如KetamaConnectionFactory使用的Ketama一致性哈希)。在初始化客戶端時,需要指定服務器地址列表和哈希算法。
3. 透明操作:當應用程序調用set(key, value)或get(key)方法時,客戶端內部會自動執行以下步驟:
a. 對傳入的key進行哈希計算。
b. 根據一致性哈希環,確定負責該key的目標服務器節點。
c. 從連接池中獲取與該目標節點的連接。
d. 通過該連接發送相應的Memcached協議命令進行操作。
- 故障處理:優秀的客戶端會具備節點故障檢測和移除機制。當某個節點不可達時,客戶端可以將其暫時從哈希環中剔除,并將原本路由到該節點的請求重新哈希到其他可用節點,并在節點恢復后將其重新加入。
三、在矩陣系統中的應用實踐
“矩陣系統”在此可理解為一種具有復雜關系、多維度數據或計算密集型任務的系統(例如,社交網絡關系圖、推薦系統、實時數據分析平臺等)。在這樣的系統中,Memcached可以發揮關鍵作用。
- 應用場景:
- 關系鏈緩存:在社交矩陣中,用戶的好友列表、關注關系是頻繁訪問但變更相對不頻繁的數據。可以將其以序列化對象的形式緩存,key為用戶ID,大幅減少對關系數據庫的圖查詢壓力。
- 計算結果緩存:矩陣運算、個性化推薦結果、熱門排行榜等計算成本高的結果,可以緩存一定時間(設置過期時間)。例如,將“用戶A的推薦內容列表”作為緩存項。
- 會話與狀態共享:在分布式部署的矩陣計算節點或Web服務前端之間,共享用戶會話狀態,實現無狀態服務架構。
- 鎖與協調:利用Memcached的
add命令(原子性)實現簡單的分布式鎖,用于控制對矩陣中某個資源(如特定數據塊的更新)的并發訪問。
- 實現考量:
- Key設計:需要精心設計緩存鍵,確保其唯一性和可讀性。例如,對于用戶關系,key可以是
REL:U:{userId}:FOLLOWERS。對于矩陣塊數據,key可以是MATRIX:{matrixId}:BLOCK:{row}:{col}。
- 序列化:Java對象需要高效地序列化為字節數組進行存儲。除了Java原生序列化,可以考慮更高效的方案如Kryo、Protobuf等,并在客戶端配置相應的轉換器。
- 過期策略:根據數據特性設置合理的過期時間。靜態關系可以設置較長TTL,動態計算結果則設置較短TTL并配合主動更新。
- 緩存穿透與雪崩:對于不存在的key(緩存穿透),可以在緩存中設置一個空值標記。對于大量key同時過期(雪崩),可以給過期時間加上隨機擾動。
- 客戶端配置:根據矩陣系統的規模和訪問模式,優化客戶端連接池參數、哈希算法選擇、故障轉移策略等。
****
Memcached通過客戶端驅動的一致性哈希實現了高效、可擴展的分布式緩存。在Java中,借助成熟的客戶端庫,開發者可以便捷地將此能力集成到應用中。面對矩陣系統這類數據關系復雜、計算需求高的場景,合理利用Memcached對熱點數據、中間結果和共享狀態進行緩存,是提升系統整體性能和橫向擴展能力的關鍵架構手段之一。它并非解決所有性能問題的銀彈,但在“讀多寫少”、“計算成本高”且“數據允許暫時不一致”的場景下,其價值尤為突出。
如若轉載,請注明出處:http://www.jntaibo.cn/product/289.html
更新時間:2026-03-13 18:17:23